无
”Python Scrapy框架“ 的搜索结果
文章目录Scrapy 框架一、 简介1、 介绍2、 环境配置3、 常用命令4、 运行原理4.1 流程图4.2 部件简介4.3 运行流程二、 创建项目1、 修改配置2、 创建一个项目3、 定义数据4、 编写并提取数据5、 存储数据6、 运行...
主要介绍了python Scrapy框架的相关资料,帮助大家开始学习python 爬虫,感兴趣的朋友可以了解下
Scrapy 是一个基于 Twisted 实现的异步处理爬虫框架,该框架使用纯 Python 语言编写。Scrapy 框架应用广泛,常用于数据采集、网络监测,以及自动化测试等。提示:Twisted 是一个基于事件驱动的网络引擎框架,同样...
本文我们通过抓取Quotes网站完成了整个Scrapy的简单入门,到此为止我们应该能对Scrapy的基本用法有一个初步的概念了。不过本文内容仅仅是Scrapy所有功能的冰山一角,还有很多内容等待我们去探索,我们后续文章继续...

主要介绍了Python Scrapy框架第一个入门程序,结合实例形式分析了Python Scrapy框架项目的搭建、抓取字段设置、数据库保存等相关操作技巧,需要的朋友可以参考下
基于python scrapy框架抓取豆瓣影视资料
第一部分爬虫架构介绍 1.Spiders(自己书写的爬虫逻辑,处理url及网页等【spider genspider -t 指定模板 爬虫文件名 域名】),返回Requests给engine——> 2.engine拿到requests返回给scheduler(什么也没做)——> ...
python scrapy框架从零基础开始讲解 内有例子 关于python的别的方面的可以去我的资源页下载
主要介绍了Python Scrapy框架:通用爬虫之CrawlSpider用法,结合实例形式分析了Scrapy框架中CrawlSpider的基本使用方法,需要的朋友可以参考下
一、Scrapy框架简介Scrapy是用纯Python实现一个为了爬取网站数据,提取结构性数据而编写的应用框架,用途非常广泛。利用框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,...
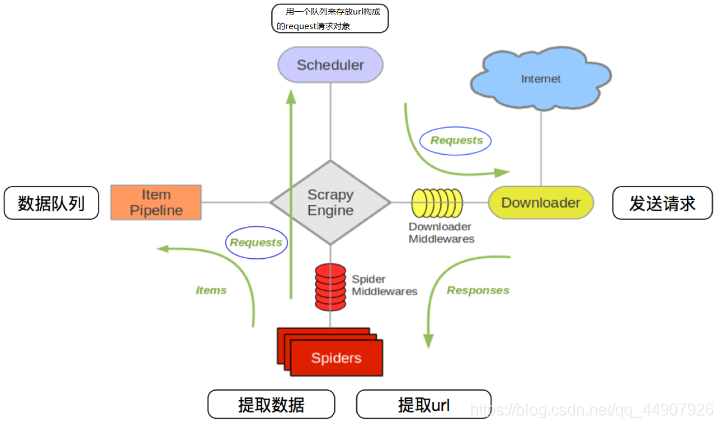
一、背景对于日常Python爬虫由于效率问题,本次测试使用多线程和Scrapy框架来实现抓取进程:优点:充分利用多核CPU(能够同时进行多个操作)缺点:系统资源消耗大,重新开辟内存空间线程:优点:共享内存,IO操作...

Scrapy是当今世界上最为强大的Python爬虫框架之一,通过Scrapy,开发者可以快速构建高效实用的爬虫,本章将带领大家学习使用Scrapy爬虫框架,编写属于自己的第一个网络爬虫。
Scrapy是一个基于Python的Web爬虫框架,可以快速方便地从互联网上获取数据并进行处理。它的设计思想是基于Twisted异步...本教程将介绍如何使用Scrapy框架来编写一个简单的爬虫,从而让您了解Scrapy框架的基本使用方法。
本教程将实际操作使用Python Scrapy框架爬取传智播客教师页面教师的个人信息。 爬取页面网址:http://www.itcast.cn/channel/teacher.shtml#ac Scrapy,Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于...

一、Scrapy框架简介Scrapy是用纯Python实现一个为了爬取网站数据,提取结构性数据而编写的应用框架,用途非常广泛。利用框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,...


整个工程是使用的python3.6+Scray框架+MySQL数据库. 整个项目是在一个github开源的项目的基础上进行修改. 由于整个项目具有保密性,所以源码就不能放出了,下面和大家交流思路. 未完待续,有空我就会更新一下. 0....
Scrapy 是一个基于 Twisted 实现的异步处理爬虫框架,该框架使用纯 Python 语言编写。Scrapy 框架应用广泛,常用于数据采集、网络监测,以及自动化测试等。
1.什么是状态码301301 Moved Permanently(永久重定向) 被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个URI之一。如果可能,拥有链接编辑功能的客户端应当自动把请求的地址...

headers = { 'Content-Type': 'application/json; charset=UTF-8', # host没有https:// 'Host': 'www.sasclouds.com' } 注意Host是没有http://等请求头的
推荐文章
- 机器学习之超参数优化 - 网格优化方法(随机网格搜索)_网格搜索参数优化-程序员宅基地
- Lumina网络进入SDN市场-程序员宅基地
- python引用传递的区别_php传值引用的区别-程序员宅基地
- 《TCP/IP详解 卷2》 笔记: 简介_tcpip详解卷二有必要看吗-程序员宅基地
- 饺子播放器Jzvd使用过程中遇到的问题汇总-程序员宅基地
- python- flask current_app详解,与 current_app._get_current_object()的区别以及异步发送邮件实例-程序员宅基地
- 堪比ps的mac修图软件 Pixelmator Pro 2.0.6中文版 支持Silicon M1_pixelmator堆栈-程序员宅基地
- 「USACO2015」 最大流 - 树上差分_usaco 差分-程序员宅基地
- Leetcode #315: 计算右侧小于当前元素的个数_找元素右边比他小的数字-程序员宅基地
- HTTP图解读书笔记(第六章 HTTP首部)响应首部字段_web响应的首部内容-程序员宅基地